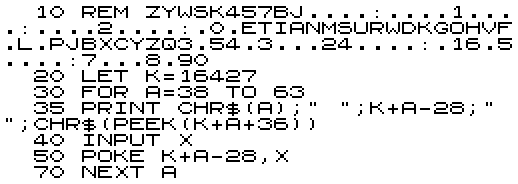Introduction
After porting Mini Morse from the ZX81 to the ZX80, it occurred to me that Mini Morse would be a good candidate for converting to a classic Macintosh. I used my original introduction to classic Macintosh programming: Inside The Toolbox with Think Pascal.
I have that book, but used it to develop programs using Think C 5.0.4, because I had a proper copy of that; it works in a similar way and I'm more comfortable with C instead of Pascal. It turned out that it was fairly straightforward and satisfying to code, with the final application coming in at 3020 bytes.
Digital Archeology
Unfortunately, although Think C is readily available, I'm not sure of its legal status with regard to copying, even though it's abandonware. However, I am aware that Think Pascal, certainly up to version 4.5.4 at the end of its development is available for downloads for personal use.
I had had a version of Think Pascal 4.5.4 downloaded well over a decade ago, and had used it for some minor projects. Again, unfortunately, it's not easy to download. The web page still exists, but the Symantec link it uses at the time is now broken.
So, initially I ported my Mini Morse program to my Think Pascal 4.5.4, which I copied indirectly from my PowerBook 1400c (via a SCSI Zip drive and USB Zip drive). Then I found that the application it created, was about 16kB long. It seemed very unlikely to me that a straightforward Toolbox program, converted from Think C 5 for a Mac 7 Toolbox geared for Pascal would be that much bigger. And this lead me to the conclusion that Think Pascal 4.5.4 is not such a great IDE for early era Mac application development.
Then began the quest to see if it was any better under an earlier version. It turns out that Think Pascal 4.0.2 is available from a number of sources including Macintosh Garden, but the source I would trust the most is the link from MacGui.com. This downloads a Stuffit .sit file. You'll also need to download ResEdit, which you can from the same site here as a disk image.
Now, Stuffit still exists as a format for compressing Mac and Windows files, but the .sit file in question can't be expanded by the version of Stuffit Lite I had on my miniVMac emulator (as this Stuffit Lite was too early), and it couldn't be expanded by a later version of Stuffit Lite (because the compression format is no longer supported). After several approaches, I found that my iMac G3 running Mac OS 9 had a version of Stuffit that could expand that file, but I couldn't then use it to compress it so that it could work with Stuffit Lite on miniVMac.
In the end, I took a different approach. I used Disk Copy on the iMac G3 to create a .img disk image from the Think Pascal folder; which I could then open as a disk on miniVMac. From here I could create a new project in Think Pascal 4.0.2, which, when compiled as an application, took up only 2803 bytes.
This illustrates an increasing issue with the maintenance of retro software on modern platforms, via emulation or other means: the number of bridging technologies is becoming more convoluted as modern systems leave behind archaic technology. It's why I think I have to, or ought to maintain a number of Macs between my oldest (a 68000 Mac Plus from the 1986 era) to my MacBook Pro from 2018 via a Performa 400 (68030 Colour Mac) PowerBook 1400C (an early PowerPC Mac which runs System 7.5.3 and Mac OS 8.1 reasonable); iMac G3 (which runs Mac OS 9.2 and Mac OS X 10.3 OK); Mac Book Core Duo (which runs up to Mac OS X 10.6.8). Using these machines gives me a continuity of technology.
Running MiniMorse For 68K Mac
The purpose of this blog is to show how compact a 1kB ZX81 program can be on an early GUI computer. The ZX81 was a simple text-based 8-bit home computer which could officially support up to 16kB of RAM, but came with 1kB of RAM as default, along with its programming language, in an 8kB ROM.
The early Macintosh was a major conceptual leap in computing, supporting a sophisticated (for the time) Graphical User Interface with Windows, Icons, Menus and directly controllable gadgets. The earliest versions used a 32-bit, 68000 CPU and provided 128x the memory of a ZX81, with 8x the ROM. I never had the opportunity to use one of these machines directly, but at the
University Of East Anglia, where I did my Computer Science BSc, they had the next model, with 512kB of RAM. These Macs could run simple development environments such as the interpreted Mac Pascal; or
ETH Modula-2.
So, it's a natural question to ask how much more bloated equivalent applications were, on computers with that level of sophistication and about 8x to 32x the resources. And the answer, as far as Macs go, is that they are proportionally more sophisticated (a 3kB program / 400 bytes is about 7.5x larger).
What is really different is the length of the program itself. The ZX81 program is tokenised, so the source code for the version that takes up just under 400 bytes, is also 400 bytes, because the source is the final program. On the other hand, the Mac Pascal version takes up nearly 7kB of source code, around 17x larger, even though it compiles into a program only 7.5x larger.
The MiniMorse application can be found
here. Download it onto your computer. You'll need a means of converting from .hqx to the application itself, but in https://system7.app that's easy. First you need to copy the file, by opening "The Outside World" server then dragging the MiniMorse app onto the Downloads folder. Drag the .hqx file to The Infinite Hard Disk. Then you open Infinite HD:Utilities:Compact Pro; Open Compact Pro and select Misc:Convert FROM Bin Hex. Navigate to the .hqx file in The Infinite Hard Disk and then save the Application in the same location. After a few seconds, the application appears in The Infinite Hard Disk.
Double-click the application to run it. You'll see a simple Mac Application:
As with the ZX81 version, typing a letter or digit generates the Morse code and typing a morse code generates the letter or digit. In addition to the ZX81 program, like a good Macintosh application MiniMorse sets the cursor to an arrow (as you can see), supports an about dialog:
And a Quit option with the command Q short-cut.
You'll find that MiniMorseMac handles window updates properly, can move to the back or front and can launch a desk accessory. It should work with Multifinder under System 6 or earlier or simply the Finder. You can shrink the memory allocation down to about 16kB and it will work fine.
Typing In The Program
MiniMorse Mac is short enough to type in. So, here's how to create the application from scratch. Firstly, create a folder called DevProjects and within it, create a folder called MiniMorse. This is where the Pascal project will go.
Next, run Think Pascal. It might complain that it needs 4MB to run, but it doesn't. Change the memory allocation to just 1MB and it'll be fine (From the Finder, choose File:Get Info on the application and change the box on the bottom right).
When you run Think Pascal, it will want to start with a project. Navigate to the MiniMorse folder and click on [New]. It will ask for a project name, type MiniMorse.π ('π' is option+p). Don't create an instant project, click on Done and the project window will be created. Save and then Quit.
The next step is to create the resources. Find ResEdit 2.1 and open the application. Create a new file and call it MiniMorse.π.rsrc. It's fairly tricky to describe how create resources interactively, but the following table should condense the information. You may find that the WIND, DITL and ALRT resources have fields for Width and Height instead of Right and Bottom, in which case the e.g. WIND menu will give you an option to switch the fields. Finally, [¹] means choose Resource:Create New Resource... (Command)K; [²] means choose Resource:Get Resource Info... (Command)I and in menus, [ENTER] means you literally need to press the [ENTER] key.:
| Re-source¹ |
Fields.. [Close Window] |
Info².. [Close, Close] |
| WIND [OK] |
TOP=40, Bottom=240, Left=40, Right=280, Initially Visible, Close Box, Default Color |
ID=400, Name="MiniMorse", Purgeable (only) |
| MENU [OK] |
[X] Enabled, Title=• Apple Menu[ENTER], [X] Enabled, Title="About MiniMorse..."[ENTER] [ ]Enabled, • Separator line |
ID=128, No attributes. |
| MENU [OK] |
[X] Enabled, Title="File"[ENTER], [X] Enabled, Title="Quit", Cmd-Key:Q[ENTER] |
ID=129, No attributes. |
| DITL [OK] |
Drag [Static Text] to DITL and double-click it. [X] Enabled. Text="MiniMorse ©2023 Julian Skidmore[ENTER]Press a letter or digit to convert to Morse code, or press a sequence of '-' and '.' to convert a letter/digit", Top:4, Bottom:73, Left:64, Right:311. Close, Drag Button below Text. Double-click it. [X] Enabled. Text="OK" Top:90, Bottom:110, Left:159, Right:217. Close. |
ID=400, Only attribute=Purgeable. |
| ALRT [OK] |
Color:Default, DITL ID=400, Top:40, Bottom:240, Left:40, Right:280 |
ID=400, Only attribute=Purgeable. |
When you've finished, close the .rsrc file. ResEdit will ask you to save it - save it. Then open up the MiniMorse.π project. Choose File:New and create a stub of a pascal program:
program MiniMorse;
begin
end.
Choose File:Save to save it as MiniMorse.p. Choose Project:Add "MiniMorse.p" to add the file to the project. Next, add the resource file by choosing Run:Run Options... Tick the [ ] Use Resource File field and then choose the MiniMorse.π.rsrc file you created. Finally, Click [OK].
Now you want to replace the dummy program with the rest of file. When you've finished...
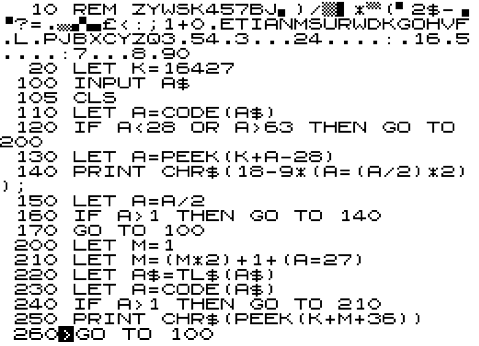
program MiniMorse;
const
kWindIdBase = 400;
kMenuBarId = kWindIdBase;
kMenuIdApple = 128;
kMenuAbout = 1;
kMenuIdFile = 129;
kMenuQuit = 1;
kAboutAlertId = 400;
kWneTrapNum = $60;
kUnimplTrapNum = $9f;
{ We want to support a 1s event timeout. }
kSleep = $60;
kOriginX = 10;
kOriginY = 10;
kMaxMorseLen = 5;
kTapMax = 15;
kMorseLetterCodes = 26;
{ 0..9=0..9, 10..16 :;<=>?@}
{17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30}
{A B C D E F G H I J K L M N}
gLettersToMorse = '6AE92D;@4N=B75?FK:83<H>>IMC';
kMorseDigitCodes = 10;
gDigitsToMorse = '_^\XP@ACGO';
kMorseCodes = 64;
gMorseToAlpha = '0.ETIANMSURWDKGOHVF.L.PJBXCYZQ3.54.3...24....:.16.5....:7...8.90';
cMorseSyms = '.-';
var
gMorseWin: WindowPtr;
gDone, gWNEImplemented: boolean;
gTheEvent: EventRecord;
gHelloStr, gNumStr: Str255;
gMorseStr: string[6];
gKeyCode, gMorseSyms: string[2];
gUpdates, gMorseTap: integer;
gTapTimeout: longint;
{ 0.5s timeout }
function Later (aTimeout: LONGINT): LONGINT;
begin
Later := TickCount + aTimeout;
end;
function After (aTimeout: LONGINT): boolean;
var
tick: longint;
timedOut: boolean;
begin
tick := TickCount;
timedOut := aTimeout - tick < 0;
After := timedOut;
end;
function DoMenuBarInit: boolean;
var
menu: MenuHandle;
begin
menu := nil;
menu := GetMenu(128);
AddResMenu(menu, 'DRVR');
InsertMenu(menu, 0); { add after all.}
menu := NewMenu(129, 'File');
AppendMenu(menu, 'Quit/Q');
InsertMenu(menu, 0);
DrawMenuBar;
end;
function Init: boolean;
var
fontNum: integer;
ok: boolean;
begin
gDone := false;
gUpdates := 0;
gKeyCode := ' ';
gMorseStr := ' ';
gMorseTap := 1;
gMorseSyms := '.-';
gTapTimeout := Later(kTapMax);
gWNEImplemented := NGetTrapAddress(kWindIdBase, ToolTrap) <> NGetTrapAddress(kUnimplTrapNum, ToolTrap);
gMorseWin := GetNewWindow(kWindIdBase, nil, WindowPtr(-1));
ok := gMorseWin <> nil;
if ok then
begin
SetWTitle(gMorseWin, 'MiniMorse');
SetPort(gMorseWin);
GetFNum('monaco', fontNum);
TextFont(fontNum);
TextSize(9); { just standard size.}
ShowWindow(gMorseWin);
ok := DoMenuBarInit;
if ok then
InitCursor;
end;
Init := ok;
end;
procedure DoMenuApple (aItem: integer);
var
accName: Str255;
accNumber, itemNumber, dummy: integer;
appleMenu: MenuHandle;
begin
case aItem of
kMenuAbout:
dummy := NoteAlert(kAboutAlertId, nil);
otherwise
begin
appleMenu := GetMHandle(kMenuIdApple);
GetItem(appleMenu, aItem, accName);
accNumber := OpenDeskAcc(accName);
end;
end;
end;
procedure DoMenuFile (aItem: integer);
begin
case aItem of
kMenuQuit:
gDone := true;
end;
end;
procedure DoMenuChoice (aMenuChoice: LONGINT);
var
menu, item: integer;
begin
if aMenuChoice <> 0 then
begin
menu := HiWord(aMenuChoice);
item := LoWord(aMenuChoice);
case menu of
kMenuIdApple:
DoMenuApple(item);
kMenuIdFile:
DoMenuFile(item);
end;
HiliteMenu(0);
end;
end;
procedure DoMouseDown;
var
whichWindow: WindowPtr;
thePart: integer;
windSize, menuChoice: LONGINT;
oldPort: GrafPtr;
begin
thePart := FindWindow(gTheEvent.where, whichWindow);
case thePart of
inMenuBar:
begin
menuChoice := MenuSelect(gTheEvent.where);
DoMenuChoice(menuChoice);
end;
inSysWindow:
SystemClick(gTheEvent, whichWindow);
inDrag:
DragWindow(whichWindow, gTheEvent.where, screenBits.bounds);
inContent:
if whichWindow <> FrontWindow then
begin
SelectWindow(whichWindow);
end;
inGrow:
; { don't support.}
inGoAway:
gDone := true;
inZoomIn:
;
inZoomOut:
; { don't support.}
end;
end;
procedure Repaint (aWindow: WindowPtr);
var
oldPort: GrafPtr;
begin
GetPort(oldPort);
SetPort(aWindow);
{ tempRgn=NewRgn;}
{ GetClip(tempRgn);}
EraseRect(aWindow^.portRect);
MoveTo(kOriginX, kOriginY);
{ DrawString('Updates=');}
{ NumToString(++gUpdates, gNumStr);}
{ DrawString(gNumStr);}
DrawString('Key=');
DrawString(gKeyCode);
{ MoveTo(kOriginX, kOriginY+10);}
DrawString(' Morse=');
DrawString(gMorseStr);
SetPort(oldPort);
end;
procedure DoUpdate (aWindow: WindowPtr);
var
myRect, drawingClipRect: Rect;
oldPort: GrafPtr;
tempRgn: RgnHandle;
begin
BeginUpdate(aWindow);
if aWindow = gMorseWin then
begin
{ DrawMyStuff}
Repaint(aWindow);
end;
EndUpdate(aWindow);
end;
{ @ brief , handle Key Event , assume Later bottom byte .}
{Keys aren 't sent to it now.}
procedure DoKey;
var
ch: char;
len, morseCode: integer;
begin
ch := char(BitAnd(gTheEvent.message, 255));
if BitAnd(gTheEvent.modifiers, cmdKey) = cmdKey then
begin
DoMenuChoice(MenuKey(ch));
end
else
begin
morseCode := 1;
len := 0;
if (ch >= '0') and (ch <= '9') then
begin
morseCode := ord(gDigitsToMorse[ord(ch) - ord('0') + 1]) - 32;
end
else if (ch >= 'a') and (ch <> 'z') or (ch >= 'A') and (ch <= 'Z') then
begin
morseCode := ord(gLettersToMorse[BitAnd(ord(ch), $1f)]) - 48;
end;
if (ch = '.') or (ch = '-') then
begin
gMorseTap := (gMorseTap * 2);
if ch = '-' then
gMorseTap := gMorseTap + 1;
gTapTimeout := Later(kTapMax);
end
else
begin
gMorseStr := ' ';
while morseCode > 1 do
begin
len := len + 1;
gMorseStr[len] := gMorseSyms[1 + BitAnd(morseCode, 1)];
morseCode := morseCode div 2;
end;
Repaint(gMorseWin);
end;
end;
end;
procedure DoNull;
var
front: WindowPtr;
begin
if (gMorseTap > 1) and After(gTapTimeout) then
begin
front := FrontWindow;
if front = gMorseWin then
begin
{ We have a valid Morse pattern!}
gKeyCode[1] := gMorseToAlpha[BitAnd(gMorseTap, 63) + 1];
Repaint(gMorseWin);
gMorseTap := 1;
end;
end;
end;
procedure DoEvent;
var
gotOne: boolean;
begin
gotOne := false;
if gWNEImplemented then
begin
gotOne := WaitNextEvent(everyEvent, gTheEvent, kTapMax, nil);
end
else
begin
SystemTask;
gotOne := GetNextEvent(everyEvent, gTheEvent);
end;
if gotOne or not (gotOne) and (gTheEvent.what = nullEvent) then
begin
case gTheEvent.what of
nullEvent: { Handle end; Morse tapping.}
DoNull;
mouseDown: { handle mousedown.}
DoMouseDown;
mouseUp:
; { handle mouse.}
keyDown:
DoKey;
updateEvt:
DoUpdate(WindowPtr(gTheEvent.message));
activateEvt:
; { Handle DoActivate;}
diskEvt:
; { don't handle.}
keyUp:
; { do nothing.}
autoKey:
;
end;
end;
end;
begin
if Init then
begin
while not (gDone) do
begin
DoEvent;
end;
end;
end.
Finally, to create the application, choose
Project:Build Application... Type a name for the application (e.g. MiniMorse), click [OK] and it should complete. Look for the compiled application and open it!
Conclusion
It's really simple to write a version of MiniMorse for a ZX81, but a lot more involved trying to create a version of the application for an early GUI environment on a Mac. It would almost certainly be much more complex still to do the same thing for Windows 3.1 or GEM (Atari ST). Nevertheless, it's possible to create a small pascal program at just under 3kB, because the Classic Mac's operating system interface is straightforward and compact.